2022. 8. 3. 21:51ㆍCloud/AWS 기초
AWS의 기능을 활용해서 실질적으로 해야하는 작업과 절차에 대해 알아보자.
AWS에서는 크게 3가지 파트로 나누어서 설명을 하고 있다.
AI서비스, ML서비스, 그리고 이 ML을 활용할 수 있는 Framework와 Infra가 있다.
먼저 AI서비스는 "완성된 형태로 바로 설정한 후 사용하기만 하면 되는 서비스"로서 서비스를 제공하고 있다.



서비스로는 비디오 및 이미지를 분석할 수 있는 완전관리형 AI기능이 있는 AWS Rekognition 서비스,
TTS(텍스트 음성 변환)서비스를 사용할 수 있는 Amazon Polly와 Amazon Transcribe,
자연어 처리(NLP)서비스를 지원해주는 Amazon Comprehend,
인공 신경망 기계 번역 서비스인 Translate, ML을 통해 제공되는 지능형 검색서비스인 kendra등이 있다.
이것 외로 Amazon Lex, Forecast, codeGrur등이 있다.

ML서비스
완전관리형인 Amazon SageMaker를 통해서 손쉽게 모델을 학습시키고, 정제하고, 발견하고 배포할 수 있는 풀스텍 서비스이다. 시각적 인터페이스 기반의 비즈니스 분석이 가능하며, 데이터 및 모델 구축, 훈련 및 대-소규모 모델 배포 및 관리를 할 수 있다.
웹 기반의 Studio IDE를 통해서 사용할 수 있는 기능으로는 내장알고리즘(혹은 사전 훈련 모델)을 사용할 수 있으며, 쥬피터 노트북 앱을 실행하는 기계학습 컴퓨팅 인스턴스를 실행할 수 있는 Notebooks기능, 회귀 중인 데이터의 손실 등의 훈련지표를 실시간으로 캡처하고 이상이 있을때마다 감지할 수 있는 Debugger, 자동으로 최상의 모델을 찾아주는 Autopilot 기능 등 다양한 기능을 제공한다.



또한 AWS에서는 어떠한 종류의 인프라를 가져와서
사용할 수 있으며, 대표적으로 TensorFlow, mxnet, PTYORCH등을 사용할 수 있다. 또한 AMI, Container 등도 사용가능하며 CPU/GPU와 같은 것들을 확장성있게 사용할 수 있으며, 단순 추론만을 위한 서비스도 제공된다.
여기서 SageMaker를 좀 더 깊게 알아보도록 하자. 훈련을 위한 데이터를 준비하거나 수집, 전개하는 과정에서 사용할 수 있다, 또한 모델을 구축할때도 당연히 사용할 수 있다. 알고리즘을 만들 수 도 있으며, 이미 만들어진 알고리즘을 사용할 수 도 있다. 이렇게 만들어진 모델을 손쉽게 훈련시키고 최적화 할 수 있는 기능도 제공한다. 훈련의 진행상황을 모니터링 할 수 도 있으며, 여러가지 상황을 조절할 수 있느 디버그 기능이 있으며, 만들어진 기능을 프로덕션에 배포하고, 모니터링 및 관리할 수 있는-배포이후의 검증 기능도 제공한다.
프리티어로 사용할 수 있으며 자세한 내용은 아래와 같다.

사용법은 간단하다. 콘솔로 접근한 후 훈련 => 훈련작업으로 접근한 뒤 훈련 작업을 생성하도록 한다.

항상 하는 이름을 지정한 후 IAM 역할을 부여한다.

이후 어떤 알고리즘을 사용할 지 지정해 준다.

이 후 머신러닝을 구동할 인스턴스를 구축해야한다. 어떤 인스턴스의 스팩에 따라 ML의 효율과 비용이 정의된다.
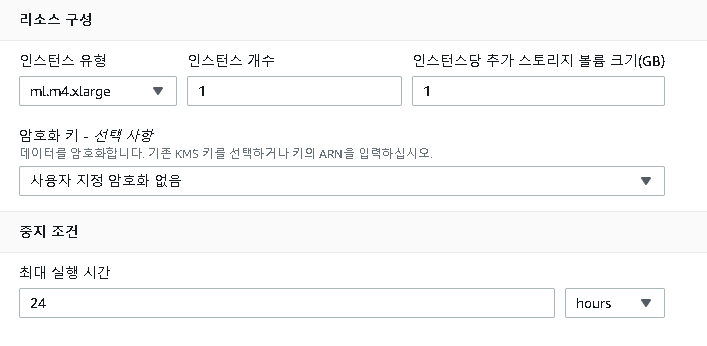
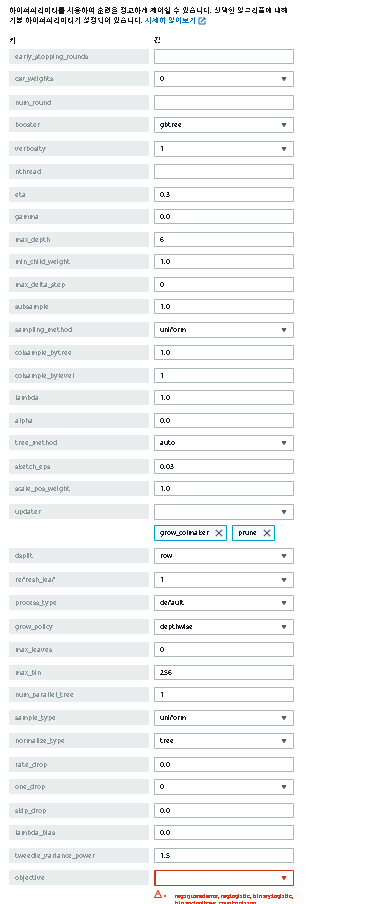
이 후 어떤 알고리즘을 선택했는지에 따라 하이퍼파라미터를 설정해야하는데 목록이 엄청나게 길기에 반드시 꼼꼼히 읽고 확인하도록 하자.
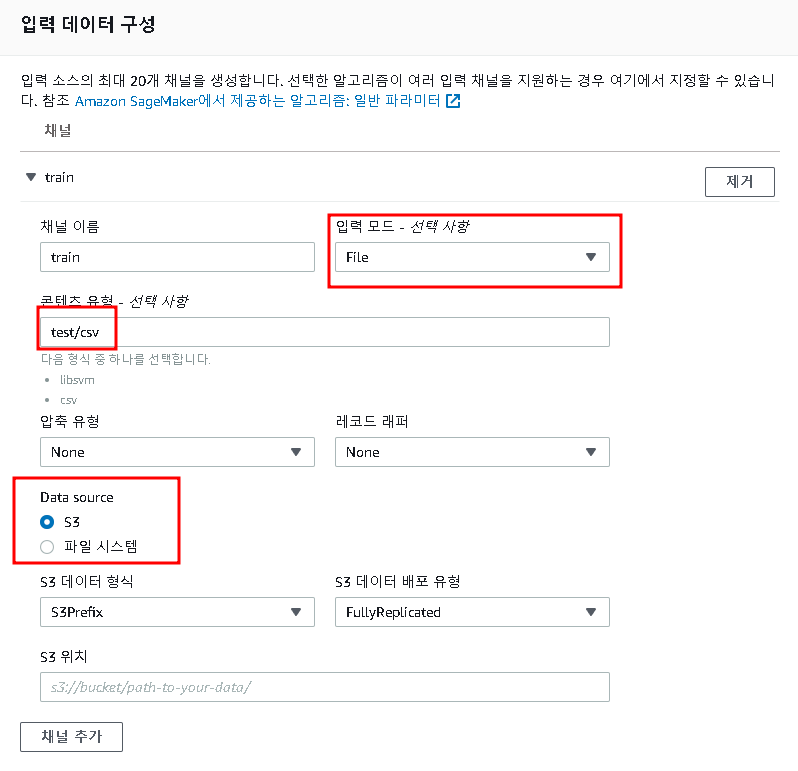
이 후 데이터 저장소와 체널이름, 입력모드, 데이터소스 등을 기입하도록 하자.
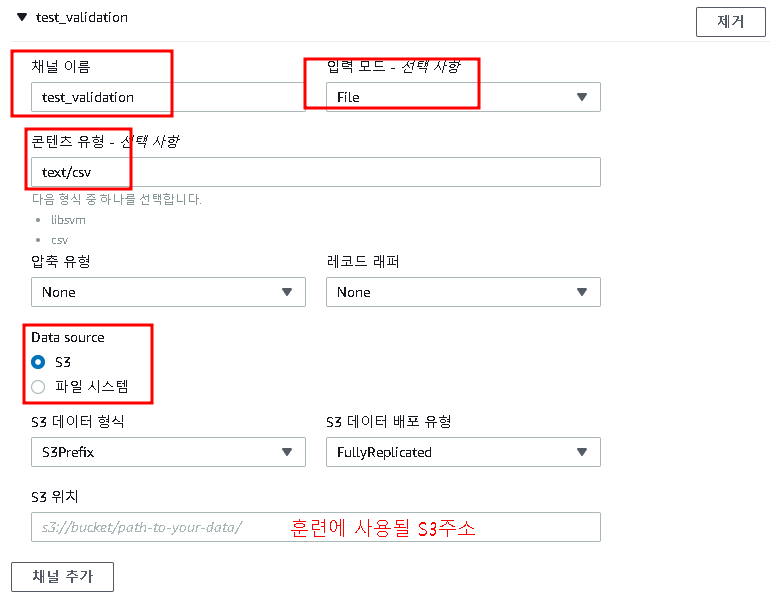
이 후 훈련받을(ML)체널을 구성하도록 하자.
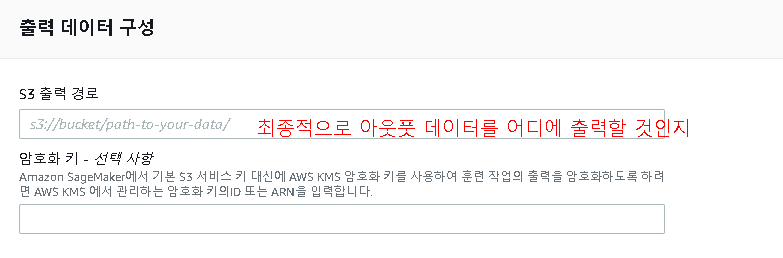
출력데이터를 어디에 저장할 것인지도 설정 하도록 하자.
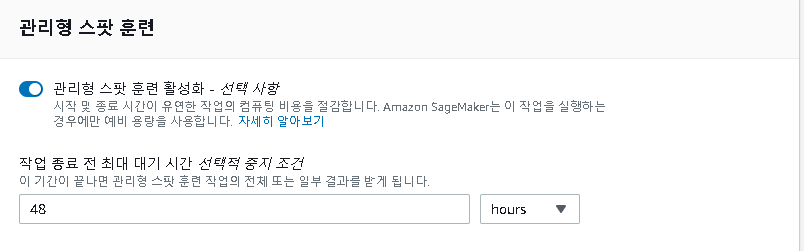
AWS에서 자랑하는 스팟 인스턴스(트레이닝)이다. 머신러닝을 활용하는데 스팟 인스턴스를 쓸지에 대한 여부를 체크하자.
머신러닝이 진행되는 동안 CloudWatch에서 트레이닝 과정을 확인할 수 있으며 트레이닝이 끝나면 SageMaker에서 확인할 수 있다.
'Cloud > AWS 기초' 카테고리의 다른 글
| AWS Resource관리(TAG/AWS 비용 관리 도구) (0) | 2022.08.05 |
|---|---|
| AWS Sage Maker 활용part.2 (AI/ML기능 활용하기) (0) | 2022.08.04 |
| AWS ECS(Elastic Container Service) (0) | 2022.07.14 |
| Amazon ElasticCache (0) | 2022.06.14 |
| AWS identity and access management(IAM) (0) | 2022.06.13 |