2022. 8. 4. 14:58ㆍ잡다한 IT
ML을 사용하기 위해서는 Pipeline을 구축할 수 있어야한다. 아래의 표는 ML에 대한 Pipeline을 도식화 해 보았다.
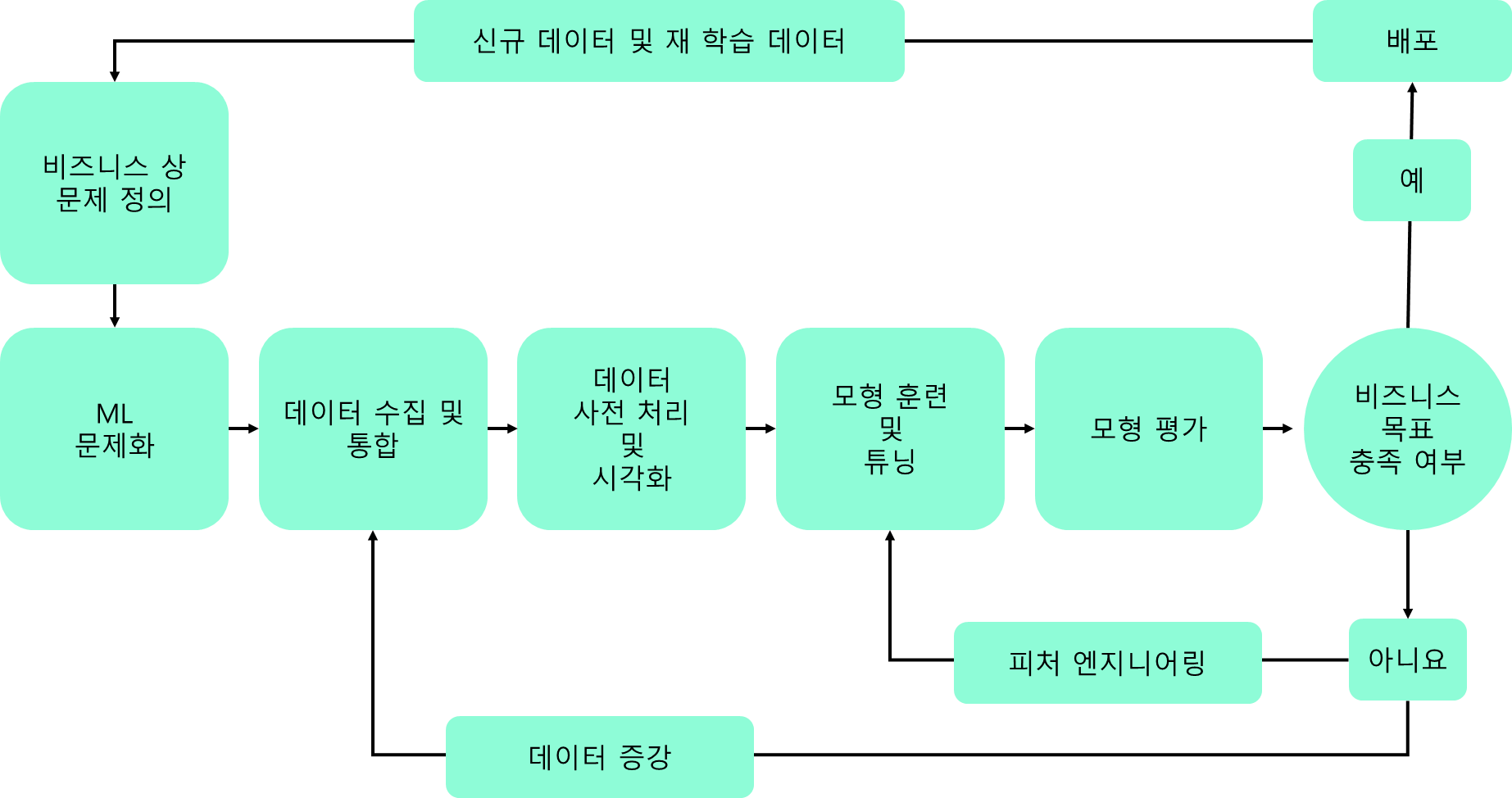
일반적으로 기업 등지에서는 인간이 해결하기 어려운 연산 혹은 대량의 자료를 분석하고 결론을 도출내기 위한 "특정 문제"를 해결하기 위해 머신러닝을 활용한다.
① 그렇기에 먼저 비즈니스 상에서 어떤 문제가 있는지를 정의할 필요가 있다. 이 작업을 해결함으로 생기는 가치가 어떤것이 있는지 등을 먼저 파악해야한다. 아무런 효용가치가 없다면 ML이라는 고급기술을 활용할 필요가 없을 것 이다. 하지만 어떤 형태와 의미를 갖던 효용성이 있다고 할때에는 고급기술을 사용하지 않을 이유가 없을 것 이다.
② 이 후 이것을 머신러닝으로 어떻게 풀어야하는가? 에 대해 고민하며 ML에 대입할 수 있는 ML문제화를 해야한다. 단순히 이러이러한 문제가 있다 라고 하는것이 아니라 ML형식으로 문제를 생성하고 자료를 수집하기 위한 문제화가 필요하다.
③ 이 문제를 풀기위해 데이터를 수집하고, 이것을 하나로 통합할 수 있어야한다. 데이터가 마구잡이로 분산되어있다면 이것을 처리하는데 굉장히 큰 불편함을 얻을 것 이다.
④ 이것을 전처리(사전 처리==> 데이터 품질 정규화) 및 시각화(어떤 가치가 있는지 분석)하는 작업을 거친 후,
⑤ 모델을 훈련시키고, 튜닝하는 작업을 해야한다.
⑥ 이때 훈련이 끝난 후 모델이 정상적으로 작동하는지 평가하며, 목표했던 결과값을 만족시킨다면
⑦ 배포 프로세스로 작동하게 될 것이다.
⑧ 하지만 검증에 실패하게 된다면 데이터 내부를 조금 더 수정하고 다듬은 후 ⑤ 다시 훈련 및 튜닝을 진행한다. 이런 반복작업 뿐 아니라,
⑨ 단순 데이터의 절대적인 양이 적을 경우 이 양을 늘리기도 한다.
⑩또한 이 배포되는 내용이 실제로 어떻게 사용되며, 배포이후 생기는 데이터를 다시 입력받아서 새로운 알고리즘을 학습하며 버전업을 하기도 한다.
'잡다한 IT' 카테고리의 다른 글
| AI/ML (0) | 2022.08.02 |
|---|---|
| The Chromium Project 0-day 이슈 (0) | 2022.04.06 |
| JSON? 제이슨? 제이슨! (0) | 2022.01.12 |
| 프론트와 벡엔드는 어떻게 서로 통신할까? (0) | 2022.01.02 |
| 개발자란 무엇일까? (0) | 2022.01.01 |